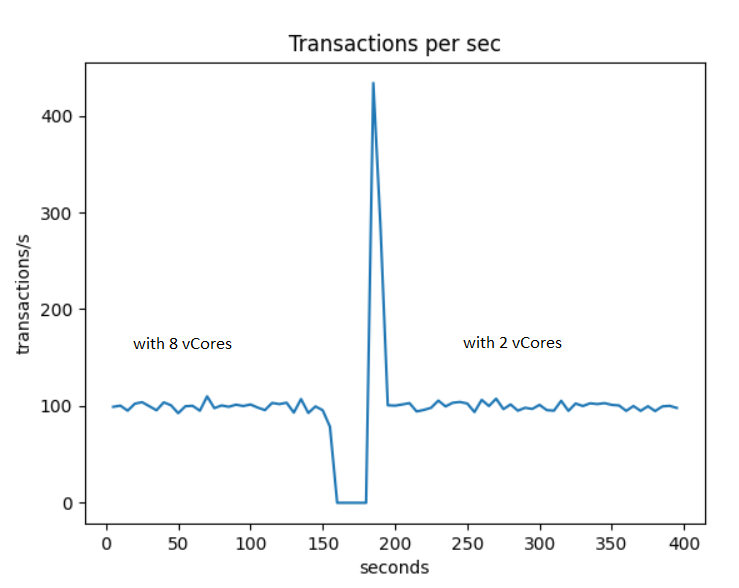
In the previous test we looked at what happened when we scaleup an Azure Database for MySQL server to sustain an heavy workload. We saw that the service interruption was minimal. Azure Database for MySQL being a fully managed DBaaS being able to scale up the service only when required by the workload is a way to optimize cost of ownership.
Scaling down is the other good way to reduce the cost of ownership. The ability to rapidly reduce the size of the machine to adjust to the real workload is critical for optimal cost management. Most real life services have seasonal spike of activity (during the day, the week or the year) and being able to adjust machine power efficiently is a real source of economy.
We will use the same protocol as we did before. wW will use sysbench to inject activity and we will add an extra options when running sysbench: --rate=100 : This will limit the number of transactions executed per second. By default sysbench runs with rate=0 which means injecting as much transaction as possible through each thread without any think time. This does not correspond to real life user behavior but that is the best way to saturate a server.
The result looks like :
After the change of pricing tier from 16 vCores to 2 vCores the transaction rate remains the same as it is sustainable by both configurations. But what is the impact of the cost of ownership. By going from a 16 vCores to 2 vCores configuration the pricing goes from an estimated 1150$/month to 150$/month. This is more than 7 times cheaper cost of ownership.
important remark :
When you decide to scale down your instance you should not look only to CPU consumption. When you change the number of vCores you change the amount of RAM. For Azure Database for MySQL each vCores adds 5G of RAM. As MySQL relies on caching changing the hit ratio for the cache can degrade performance more than CPU only arithmetic would predict.
Do not forget your replicas 😉 If you use multiple read replicas you can reduce cost by resizing replicas or even reducing the number of replicas depending on the workload.
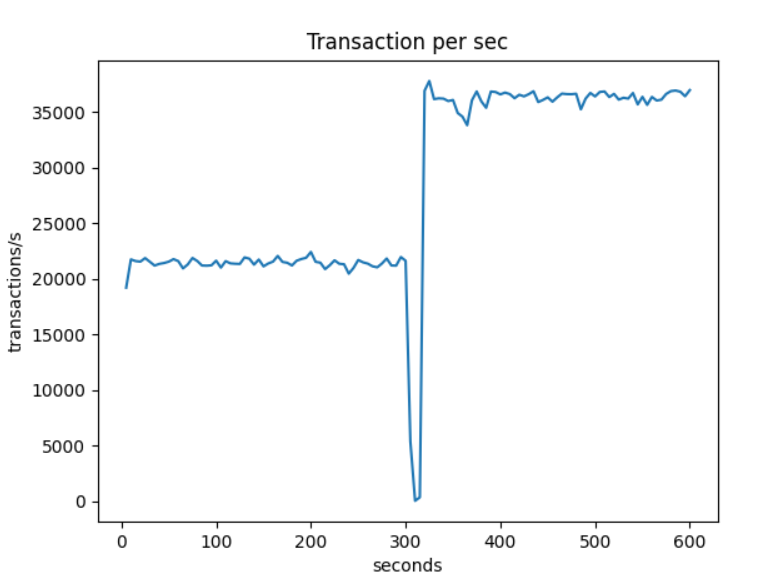
In that test I would like to measure the impact of a failover of an Azure Database for MySQL. Unfortunately there is no mechanism to force the crash of the Azure Database for MySQL instance. So how can I test how long it takes to failover and what is the impact on a server activity. Fortunately there are other circumstances where a switchover will be triggered by Azure.
For example if you decide to scale up your instance it will require (going from 2 vCores to 4 vcores in this case) a restart of the Azure MySQL container. This restart will also happen without any action on your side when Azure decides to upgrade your MySQL version.
How does this switchover behave under an heavy workload. To generate an heavy workload we will use sysbench with the report interval mechanism that allows to continuously track transactions per second(tps).
We will add 2 extra options when running sysbench: --mysql-ignore-errors=all : this will ignore connection errors and trigger a reconnection. The normal behavior of sysbench is to not use the failed connection anymore --db-ps-mode=disable : this is to disable prepared statement as it is incompatible with reconnection
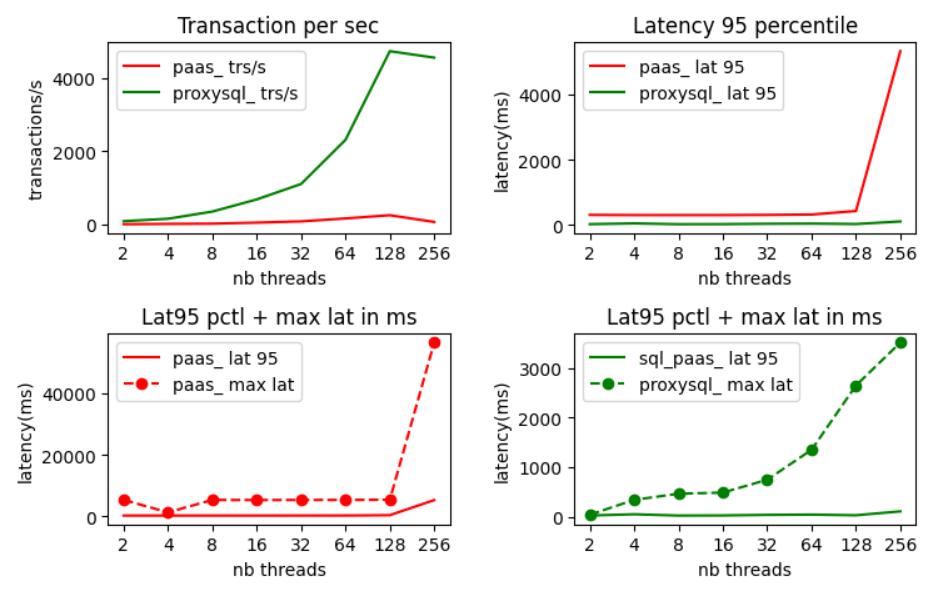
To see if we get benefit from a scaleup We will use a workload that is above what can be handled by the initial server(2 vCores). The scale up aim is to have a new server that can sustain the initially required level of activity. A real life situation would be to scale the MySQL database that is behind your ecommerce/Magento website when seasonal high traffic happens.
What we see here is a positive result :
- The scale up took place in a reasonable amount of time (around 10s)
- The new scaled up server having more vCores(4 vCores) was able to offer a higher number of transactions per second(almost twice).
In the 2 previous posts(1/3, 2/3) I gave you feedback about an experiment I made with ProxySQL and connection redirection. I used sysbench 1.1 with parameter ”reconnect=1" which force reconnect after every query. This was to represent a PHP application for which you get connection at each page. I used the script 'oltp_point_select.lua' not to have too much stress on the database.
In this new test I will keep connections open during all the run without re-connection. To do so I will run sysbench 1.1 with parameter ”reconnect=0". This is the exact opposite of what we did before. We will have long running connection through which lots of queries will go. This is by the way is the default behavior of sysbench with no reconnect parameter. In that case at startup sysbench open a set of threads/connections and run all transactions through them without reconnecting and just committing when necessary.
Keeping the connections open will mimic the behavior you can for example with a java application server that implement connection pooling.
This test is not transactional and will just issue selects.
Like before we will test :
- normal connection through the shared gateway.
- connection through ProxySQL with redirection
- connection through standard Proxysql without redirection mechanism.
Configuration
I will use the same configuration for the Azure Database for MySQL Server : a General purpose 2 vCores 100G instance.
Sysbench and ProxySQL will run on an Azure Ubuntu VM General purpose 8 vCores / 32G RAM.
I used sysbench 1.1 with "reconnect=0” to keep the same connections open for the all duration of the injection.
I used the same script as previously ’oltp_point_select.lua' . This is a read only workload. Contrary to the two previous test there will be more stress on the database as less time will be used managing reconnection or waiting on the network.
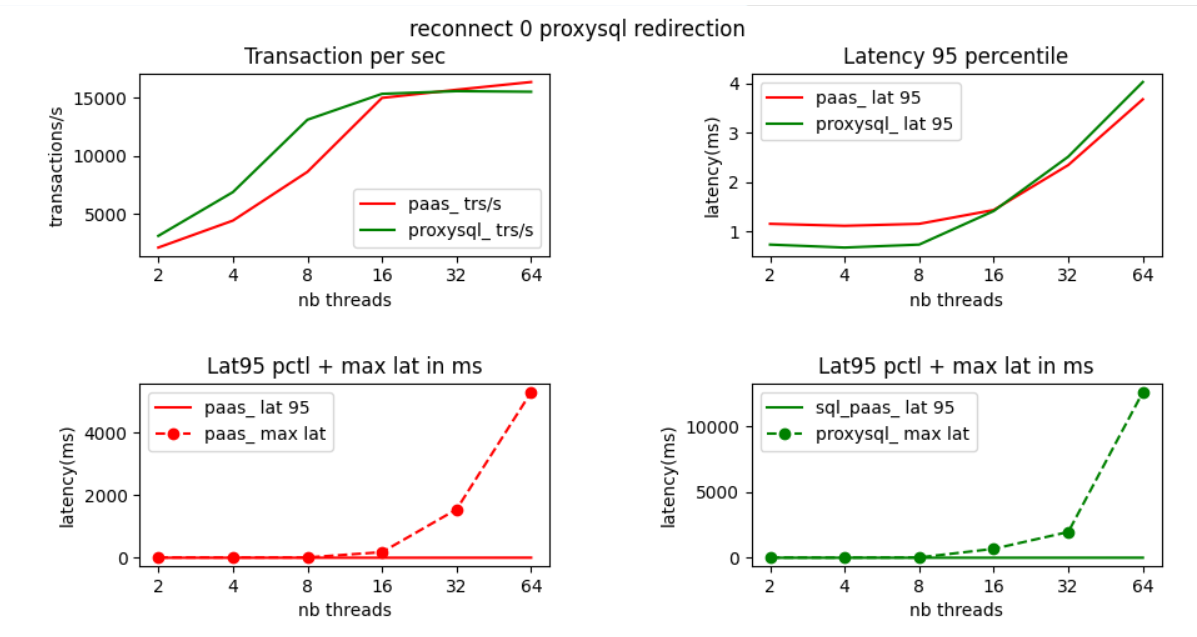
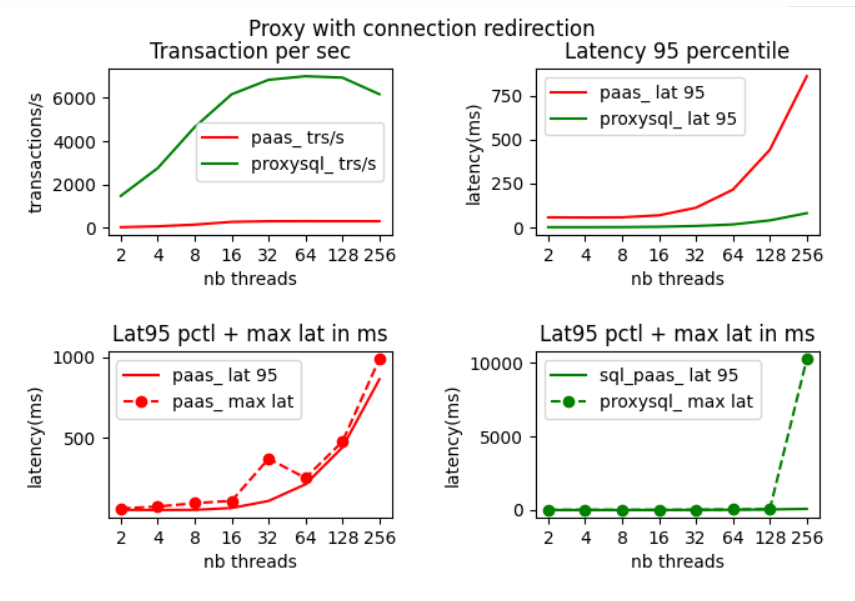
Test with ProxySQL implementing redirection
Let us look at the sysbench result with traffic going either through ProxySQL implementing redirection (green line) or through the shared gateway (red line).
When looking at these results we notice a much better throughput than with the 2 previous test. As the database server does not have to handle reconnect more queries can be executed.
What is also noticeable is that there is no much difference between max queries/s achieved going through the gateway or through ProxySQL.
When we compare for this test the throughput and latency 95 percentile result going through proxySQL are slightly better when the database server is not saturated. This is normally the area you want to operate your database in production. You load your database to 100% mostly in benchmark. This means we execute more queries faster in normal condition with redirection.
We notice also that 16 threads are enough for sysbench to saturate the database server.
If we look in more details. Here the metrics when going through the gateway (lat 95 and lat max are in ms) :
nbths
2
4
8
16
32
64
tr/s
2123
4437
8623
14968
15669
16332
lat95
1
1
1
1
2
4
latm
11
9
11
180
1545
5283
Same metrics when going through ProxySQL implementing redirection :
nbths
2
4
8
16
32
64
tr/s
3126
6881
13094
15319
15548
15495
lat95
1
1
1
1
3
4
latm
16
10
24
680
1961
12586
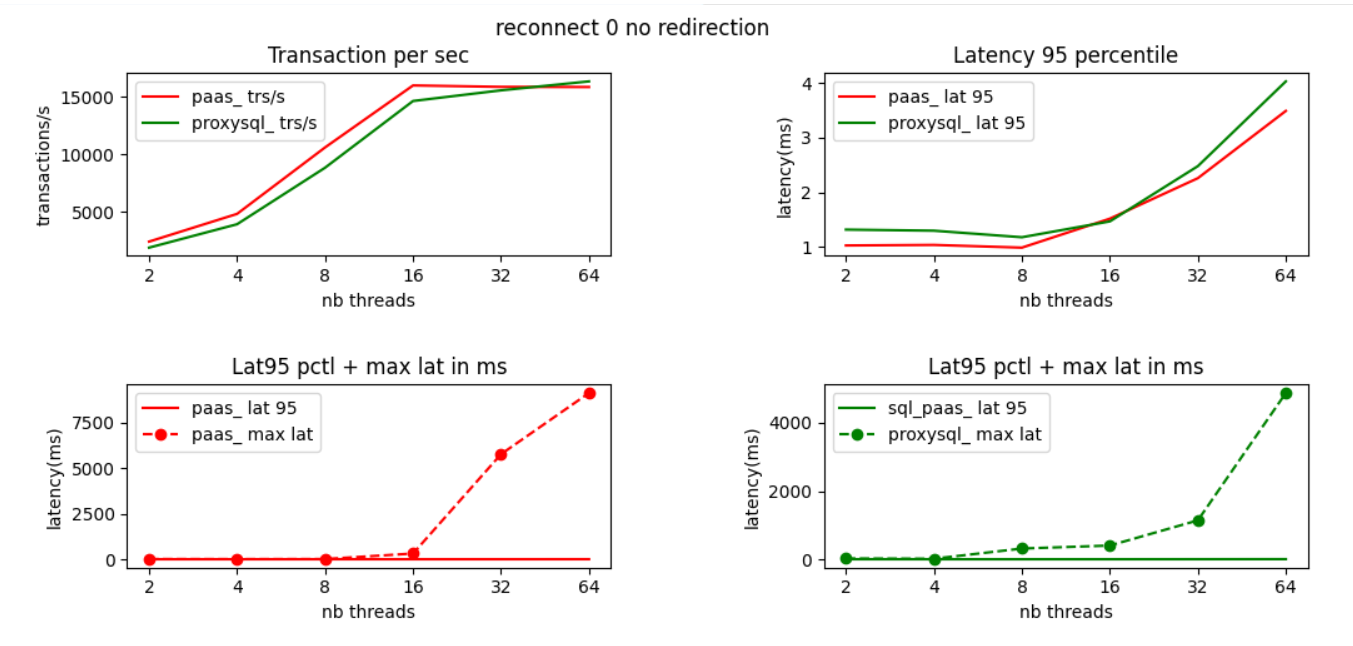
Test with ProxySQL and no redirection
Let us also now look at the sysbench result with traffic going either through standard ProxySQL with no redirection (green line) or through the shared gateway (red line).
In this second test with standard ProxySQL in front of the gateway or directly through the shared gateway the performances are almost the same. Going through ProxySQL is even slightly slower in all case as it is just an extra hop before the gateway. ProxySQL gives no benefit in that case :
nbths
2
4
8
16
32
64
tr/s
1895
3928
8837
14631
15556
16335
lat95
1
1
1
1
2
4
latm
26
17
315
403
1141
4875
Lesson learned with this third test
With this test where we used fast network ( reduced latency, bigger bandwidth) and where we keep the connection opened we were able to generate a high level of transaction/s. We executed 2x more queries per sec. There were no significant differences between the 3 approaches. Going through ProxySQL with or without redirection had very limited effect as the connection pooling was basically not used.
The connection redirection implemented in ProxySQL brings a benefit in the initial low number of threads phase. This highlight the fact that if you run a single SQL batch you will get benefit to run it by bypassing the gateway. This benefit would be there with or without ProxySQL.
The lesson learned from these 3 test is that ProxySQL and Azure Database for MySQL/MariaDB are a great fit. The connection pooling implementation gives a great benefit when there are lots of connection/s. In that case it can greatly increase the throughput you get from your Azure Database for MySQL/MariaDB.
In that same connection intensive context having ProxySQL implementing redirection show improvement in database request execution time stability.
The benefit of ProxySQL with Azure database for MySQL/MariaDB is very relevant for a wide range of languages/frameworks and applications that do not offer a connection pooling mechanism and that generate a lot of connections ( PHP, WordPress, Drupal, Magento ...). In that case ProxySQL is almost a mandatory requirement to get great performance and fully use the power of your Azure Database for MySQL/MariaDB.
Implementing connection redirection at the ProxySQL level in that context brings stability to execution time and is something that is certainly worth exploring.
My initial test was run by injecting from my Windows10 laptop WSL linux subsystem running sysbench and ProxySQL. It went through the internet to reach the Azure Database for MySQL. This is not production practice but it was deliberate to exacerbate the network impact.
But now I will redo the same test with injection coming from a VM in azure. This is definitely more realistic. The network latency will be much smaller. The VM will host sysbench and proxySQL. The VM will be in the same Azure region as the Azure Database for MySQL.
We will test the same 3 different scenario we tested :
- normal connection through the shared gateway.
- connection through ProxySQL with redirection mechanism implemented
- connection through ProxSQL without redirection mechanism.
Configuration :
Sysbench and ProxySQL will run on an Azure Ubuntu VM General purpose 8 vCores / 32G RAM. It is always great to have an injecting machine with enough resources not to be the limiting factor in the benchmark 😉
The Azure Database for MySQL Server run on General purpose 2 vCores /10G RAM /100G storage
sysbench will run with "reconnect=1" to force reconnect after every query. This is to represent a PHP application for which you get connection at each page.
I used the script 'oltp_point_select.lua' not to have too much stress on the database.
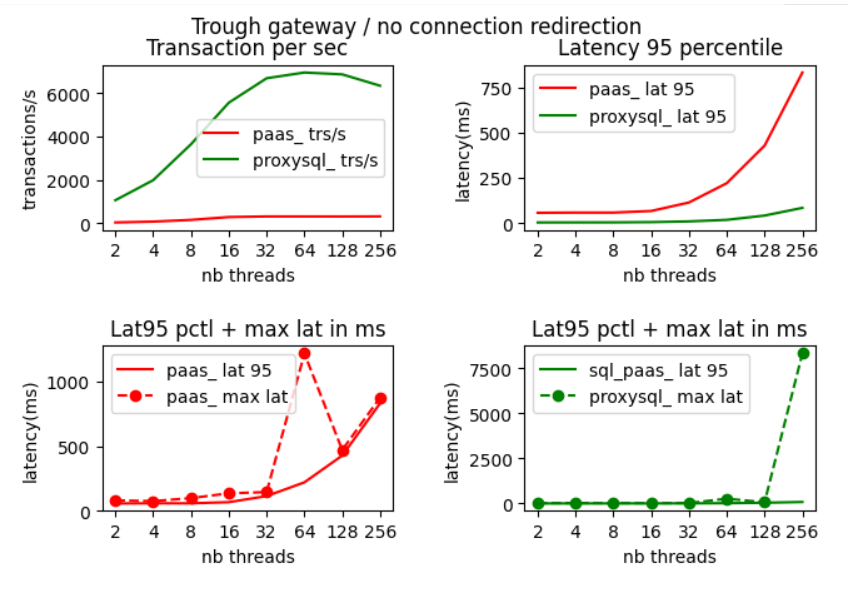
Test with ProxySQL implementing redirection
Let us look at the sysbench result with traffic going either through ProxySQL implementing redirection (green line) or through the shared gateway (red line).
When looking at these results we notice important differences :
We get a much better throughput when going through ProxySQL.
We get a much lower latency 95 percentile which means that most queries execute faster (as seen from sysbench, including network transit).
When going through ProxySQL we get a very stable execution time with small outliers. On the opposite with access through the gateway we get big outliers even under small workload.
If we look in more details. Here the metrics when going through the gateway (lat 95 and lat max are in ms) :
nbths
2
4
8
16
32
64
128
256
tr/s
38
78
156
282
313
316
313
313
lat95
58
57
58
69
113
215
443
862
latm
67
78
99
113
373
254
479
986
Same metrics when going through ProxySQL implementing redirection :
nbths
2
4
8
16
32
64
128
256
tr/s
1481
2760
4651
6161
6831
6995
6931
6166
lat95
1.79
1.82
2.22
4.1
8.58
17
40
81
latm
15
19
21
16
30
45
68
10251
Roughly when going through the proxy we get :
throughput is roughly 20X better
late 95 percentile is around 10X smaller
max latency is around 6 time smaller
Test with ProxySQL and no redirection
Let us also now look at the sysbench result with traffic going either through standard ProxySQL with no redirection (green line) or through the shared gateway (red line).
This second test is to check the benefit of ProxySQL with redirection vs standard ProxySQL. Let us look at sysbench result for the same workload on ProxySQL with no redirection :
2
4
8
16
32
64
128
256
tr/s
1063
1986
3642
5554
6679
6943
6857
6335
lat95
2.3
2.52
2.76
4.1
8.13
17
40
83
latm
21
23
24
16
24
266
67
8328
The throughput are almost the same. The only significant difference is the stability of the response time. ProxySQL with redirection gives more stable results with a smaller standard deviation. Most of the benefit comes from ProxySQL connection pooling efficiency.
Lesson learned with this second test
With a faster network ( reduced latency, bigger bandwidth) we get a bigger throughput. We also get with ProxySQL the same comparative benefit we saw in the previous post going through internet from a laptop to Azure Database for MySQL.
The lesson learned is that ProxySQL and Azure Database for MySQL/MariaDB are a great fit. The connection pooling implementation gives a great benefit. It can greatly increase the throughput you get from your Azure Database for MySQL/MariaDB.
The test with ProxySQL implementing redirection show improvement in database request execution time stability. These stability improvement in execution time with ProxySQL implementing connection redirection are worth exploring..
The benefit of ProxySQL with Azure database for MySQL/MariaDB covers a wide range of languages/frameworks and applications that do not offer a connection pooling mechanism and that generate a lot of connections ( PHP, WordPress, Drupal, Magento ...). In fact in many cases ProxySQL is a mandatory requirement to get great performance and fully use the power of your Azure Database for MySQL/MariaDB.
Implementing connection redirection at the ProxySQL level is something that is certainly worth exploring for execution time stability.
My aim here is to experiment a new approach with Azure database for MySQL/MariaDB and ProxySQL.
When a connection is initiated with Azure database for MySQL/MariaDB it goes through a shared gateway. This gateway knows where the target database server is. This level of indirection is very useful to offer High Availability in a way transparent to the client application. But by default all subsequent traffic (queries) will also go through the gateway. This extra hop create some performance penalty.
The redirection mechanism for Azure Database for MySQL
Is there a way to bypass the gateway and to directly connect to the target database and to send queries directly to the target ? : Yes. This optimization mechanism is called connection redirection in the Azure world. It needs to be activated on the PaaS Azure database to be usable by the client. Once activated the gateway will fill the last packet of the connection/authentication protocol with some extra information : the hostname of the target database the port and the username. This packet is called the OK packet in the MySQL protocol.
The OK packet that contains the address of the target database server can be analyzed by the client. This means that there can be a smart way to use this information to directly connect and send subsequent connections and queries directly to the target database.
Redirection implemented in Azure MySQL/MariaDB connectors
This is exactly what has been implemented with 2 Azure MySQL connectors that implement connection redirection : the PHP connector and the Connector J for java. To make this efficient the connector cache this information in a hashmap and direct all subsequent connection directly to the target database. A connection would only be sent to the gateway if the direct connection fails. This could happen if the HA mechanism had restarted the database on a different server.
Connection redirection implemented at the connector level is great. The only issue with this approach is that you have to use a Azure specific connectors. Currently the modifications made have not been integrated upstream and is available for a very little set of connectors. For many users that use package manager to get their software they will not get the connector version with this redirection feature. The same problem occurs if you are using software prepackaged as container images that embed a predefined version of the connector.
Making ProxySQL redirection aware ?
How can we solve this issue in an elegant way 🙂 ? Is there another approach to this problem that would not require the use of specific connectors ? Why not include this redirection feature directly in ProxySQL. In this way any application whatever the connector used will benefit from the redirection mechanism if the connection goes through ProxySQL. Many customers already use proxy SQL for connection pooling/multiplexing, load balancing, caching.
Using ProxySQL for connection redirection seems an interesting approach to explore. ProxySQL relies on MariaDB connector C library to connect to MySQL or MariaDB. During a connection to the server the gateway once the connection is correct returns an OK packet that contains all the information required to connect directly to the back-end server. Once a connection has been established through the gateway the caching of the target database is very effective as ProxySQL is a middleware used by many clients. This is less true for a connector based approach.
What we tested
This hack works but was it worth the effort ? How can we benchmark this feature to measure the benefit ? We will use sysbench with 3 different scenarii :
normal connection through the gateway. All queries will also go through the gateway. This is the behavior you get by default.
connection through ProxySQL with redirection mechanism implemented and activated
connection through Proxysql without redirection mechanism. This is the behavior you get with standard ProxySQL
Configuration
The Azure Database for MySQL Server is General purpose 2 vCores 100G
I used sysbench 1.1 to get the reconnect option that force re-connection. I used "reconnect=1" which force reconnect after every query. This is to represent a PHP application for which you get connection at each page. This is an extreme case not representative of a real workload (even though we never know 😉 )
I used the script 'oltp_point_select.lua' not to have too much stress on the database.
The first test was run by injecting from my Windows10 laptop WSL linux subsystem running sysbench and ProxySQL. It goes through the internet to reach the Azure Database for MySQL. This is not production practice but it exacerbate the network impact.
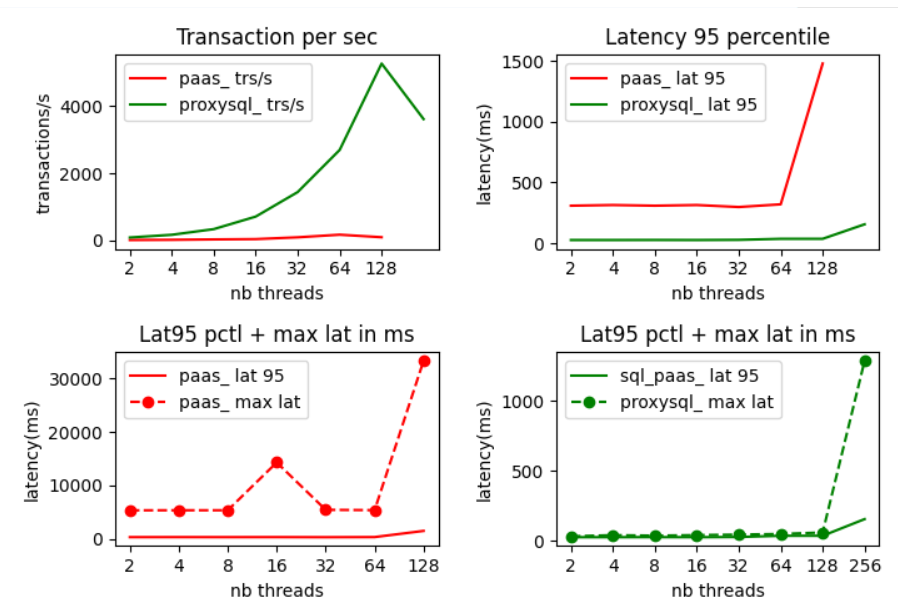
Test with proxySQL redirection
When looking at these results we notice important differences :
We get a much higher throughput when going through ProxySQL
We get a much lower latency 95 percentile which means that most queries end faster.
We get a very stable execution time with small outliers. On the opposite with access through the gateway we get big outliers even under small workload.
Test with ProxySQL and no redirection
But do these results come from the redirection or from ProxySQL. Let us look at sysbench result for the same workload :
In fact most of the benefit comes from ProxySQL. The throughput are almost the same.
The only significant difference is the stability of the response time. ProxySQL with redirection gives more stable results with a smaller standard deviation.
Lesson learned
ProxySQL and Azure Database for MySQL/MariaDB are a great fit. The connection pooling implementation gives a great benefit. This covers a wide range of languages/frameworks and applications that do not offer a connection pooling mechanism and that generate a lot of connections ( PHP, WordPress, Drupal, Magento ...). In fact in many cases ProxySQL is a mandatory requirement to get great performance and fully use the power of your Azure Database for MySQL/MariaDB.
Implementing connection redirection at the ProxySQL level is something that is certainly worth exploring for execution time stability.
If you want you can build it from source. To make a usable package you just need to have docker available. The build process through the Makefile trigger a docker container which already has all the required dependencies for building installed. For example to make a package for ubuntu 18, to install it and to run it :
$ git clone https://github.com/sysown/proxysql.git
$ cd proxysql
$ make ubuntu18
$ dpkg-i binaries/proxysql_2.0.13-ubuntu18_amd64.deb
$ sudo service proxysql start
We now have a running proxysql. Let us use it. We first create a master and 2 replicas Azure Database for MySQL. We connect to the master and create 2 users : 'sbtest' for injecting traffic and 'monitoruser' required by proxysql to monitor the backend servers :
Now we configure proxysql through the proxysql admin. At initial startup proxysql reads its configuration from /etc/proxysql.cnf. This is where the admin user credentials are defined :
All the rest of the configuration can be done in a scripted way that will be persisted to disk in a SQLite database.
mysql -h 127.0.0.1 -u proxysqladmin -pPassw0rd-P6032--sslset mysql-monitor_username='monitoruser';
set mysql-monitor_password='Passw0rd';
Let us definine the servers
insert into mysql_servers(hostgroup_id,hostname,port,weight,use_ssl, comment)
values(10,'mysqlpaasmaster.mysql.database.azure.com',3306,1,1,'Write Group');
insert into mysql_servers(hostgroup_id,hostname,port,weight,use_ssl, comment)
values(20,'mysqlpaasreplica1.mysql.database.azure.com',3306,1,1,'Read Group');
insert into mysql_servers(hostgroup_id,hostname,port,weight,use_ssl, comment)
values(20,'mysqlpaasreplica2.mysql.database.azure.com',3306,1,1,'Read Group');
We then define the 'sbtest' proxysql user. The 'sbtest' user has for default host group 10 which is the master server. That means that all queries for which no routing rules applies will end there.
insert into mysql_users(username,password,default_hostgroup,transaction_persistent)
values('sbtest','Passw0rd',10,1);
No we need to define the query routing rules that will determine to which host groups and consequently backends the queries will be routed. For Read/Write splitting that is quite simple : SELECT FOR UPDATE to 'Write group, SELECT to 'Read group' and all the rest to the default group of the user. So this means everything to 'Write group' except pure SELECT.
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)
values(1,1,'^SELECT.*FOR UPDATE$',10,1);
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)
values(2,1,'^SELECT',20,1);
Our setup for proxysql is in memory and need to be pushed to runtime an disk.
load mysql users to runtime;
load mysql servers to runtime;
load mysql query rules to runtime;
load mysql variables to runtime;
load admin variables to runtime;
save mysql users to disk;
save mysql servers to disk;
save mysql query rules to disk;
save mysql variables to disk;
save admin variables to disk;
To test our configuration we need to inject traffic. We will use sysbench for that :
We also get the digest of all the queries run and on which hostgroup they ran. We can see here that all INSERT, UPDATE,DELE were sent to the Write hostgroup and the SELECT to the Read hostgroup.
SELECT hostgroup, username, digest_text FROM stats_mysql_query_digest;
+-----------+----------+-------------------------------------------------------------+| hostgroup | username | digest_text |+-----------+----------+-------------------------------------------------------------+|10| sbtest |INSERTINTO sbtest5 (id, k, c, pad)VALUES(?, ?, ?, ?)||10| sbtest |DELETEFROM sbtest2 WHERE id=? ||10| sbtest |UPDATE sbtest2 SET c=? WHERE id=? ||20| sbtest |SELECT c FROM sbtest5 WHERE id BETWEEN ? AND ? ORDERBY c ||20| sbtest |SELECTSUM(k)FROM sbtest4 WHERE id BETWEEN ? AND ? |...
Azure Database for MySQL is a PaaS offer. It has a specific architecture that relies on a gateway. This has a huge advantage in the way it handle High availability. If a server fails it will automatically restart. The storage for the database is highly resilient and will be reconnected to the new server. You get HA out of the box without having to care about replica and failover handling.
if we look at a connection to a Azure Database for MySQL it is different from a usual MySQL connection.
mysql -h mysqlpaasmaster.mysql.database.azure.com \
-u sbtest@mysqlpaasmaster -p \
--ssl-mode=REQUIRED
we notice :
hostname : mysqlpaasmaster.mysql.database.azure.com
username : sbtest@mysqlpaasmaster
Why do we have the instance name in the username ?
If we look at what the host name is, using the unix host command (dig would also do the trick).
$ host mysqlpaasmaster.mysql.database.azure.com
mysqlpaasmaster.mysql.database.azure.com is an aliasfor cr5.northeurope1-a.control.database.windows.net.
cr5.northeurope1-a.control.database.windows.net has address 52.138.224.6
The host name is just an alias to a gateway server (it is not an A record in the DNS). So the host you connect to is specific to the database's region but carry no information about the mysql instance you connect to. This explains why when you connect you need to embed the database name into the user name. This is the only way for the gateway to know which instance you want to connect to.
Does this fit with proxySQL ? We might think No. But in fact it works perfectly with ProxySQL. ProxySQL which knows the backends hostnames is able to inject this hostname in the MySQL protocol when talking to the azure gateway. This is possible thanks to the fact that ProxySQL uses MariaDB Connector C to communicate with the gateway. With MariaDB Connector C it is possible in the connection options to add '_server_host' which contains the hostname information. In this way the gateway knows what instance is referenced without having it in the username.
ProxySQL is a fantastic technology widely used on MySQL / MariaDB architectures on premise or in the cloud. It has a nice design with the concept of host groups and query rules used to route queries to the desired backend server (based on port or regex).
To achieve this routing proxySQL uses a set of users that will potentially connect to multiple backends depending on the status of these backends and the routing query rules. This is also the same for the monitoring user that is common to all the backends.
So now to test this how this works with Azure Database for MySQL I have setup a Master with 2 replicas (that can be geo replica in another region if you wish). I have created a single user 'sbtest' in proxySQL. On this setup I run a simple sysbench to inject traffic. I use the oltp_read_write.lua script to generate insert, update, delete and select to validate that the read write splitting is working correctly. And it works like a charm 🙂
Here are the host groups, 10 for writes and 20 for reads. Hostgroup 20 contains the 2 replicas plus the master that can also be used for reads(if you want it to focus on write you can put a low weight). Hostgroup 10 contains only the master :
Through the stats we also get the digest of all the queries run and on wich hostgroup they ran. We can see here that all INSERT, UPDATE,DELE were sent to the Write hostgroup and the SELECT to the Read hostgroup.
SELECT hostgroup, username, digest_text FROM stats_mysql_query_digest;
+-----------+----------+-------------------------------------------------------------+| hostgroup | username | digest_text |+-----------+----------+-------------------------------------------------------------+|10| sbtest |INSERTINTO sbtest5 (id, k, c, pad)VALUES(?, ?, ?, ?)||10| sbtest |DELETEFROM sbtest2 WHERE id=? ||10| sbtest |UPDATE sbtest2 SET c=? WHERE id=? ||20| sbtest |SELECT c FROM sbtest5 WHERE id BETWEEN ? AND ? ORDERBY c ||20| sbtest |SELECTSUM(k)FROM sbtest4 WHERE id BETWEEN ? AND ? |...
In the monitor schema we will find data that has been collected by the 'monitoruser'. In the monitor schema we can find log data for connect, ping, read_only ... Here for example the ping data to check the availability of the backends :
MySQL >SELECT hostname FROM mysql_server_ping_log;
+--------------------------------------------+------+------------------+------------+| hostname | port | time_start_us | ping_success_time_us |+--------------------------------------------+------+------------------+------------+| mysqlpaasreplica1.mysql.database.azure.com |3306|1591785759257052|20088|| mysqlpaasreplica2.mysql.database.azure.com |3306|1591785759269801|19948|| mysqlpaasmaster.mysql.database.azure.com |3306|1591785759282430|19831|
I hope this helped you understand how ProxySQL work with Azure Database for MySQL/MariaDB.
The use of proxySQL on Azure with Azure Database for MySQL/MariaDB definitely brings a lot of value.
In previous post I used Terraform to provision a managed version of MariaDB (AWS RDS for MariaDB). There exist various managed version of MariaDB on the major cloud providers : AWS, Azure, Alibaba Cloud. All of these versions offer a simplification to rapidly deploy and operate MariaDB. You benefit from easy setup including High availability and backup policies. This is nice But what if you want to fully control your MariaDB setup, configuration, and operation procedures.
A pragmatic approach is to use a Docker containerized version of MariaDB and to run it on a kubernetes cluster. Using Kubernetes as an orchestrator and MariaDB Docker images as building blocks is a good choice to remain cloud agnostic and to be prepared for multicloud architectures.
But Kubernetes can be a complex beast. Installing kubernetes, keeping it highly available and maintaining it up to date can consume a lot of time/ressources.
It makes a lot of sense to use a managed version of kubernetes like Azure Kubernetes Service(AKS). It is economically interesting as with AKS we do not pay for the kubernetes control plane. Kubernetes itself is a standard building block that offers the same features on all cloud providers. Kubernetes is a graduated project of the Cloud Native computing foundation and this is a strong guaranty of interoperability across different cloud providers.
First let us login to Azure and set the SUBSCRIPTION_ID to the subscription we want to use to create the principal.
$ az login
To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code XXX to authenticate.
[{
"cloudName": "AzureCloud",
"id": "07ea84f6-0ca4-4f66-ad4c-f145fdb9fc39",
"isDefault": true,
"name": "Visual Studio Ultimate",
"state": "Enabled",
"tenantId": "e1be9ce1-c3be-436c-af1d-46ffecf854cd",
"user": {
"name": "serge@gmail.com",
"type": "user"}}]
$ az account show --query "{subscriptionId:id, tenantId:tenantId}"{
"subscriptionId": "07ea84f6-0ca4-4f66-ad4c-f145fdb9fc39",
"tenantId": "e1be9ce1-c3be-436c-af1d-46feecf854cd"}
$ export SUBSCRIPTION_ID="07ea84f6-0ca4-4f66-ad4c-f145fdb9fc39"
We first need to create an Azure AD service principal. This is the service account that will be used by Terraform to create resources in Azure.
$ az ad sp create-for-rbac --role="Contributor" --scopes="/subscriptions/${SUBSCRIPTION_ID}"{
"appId": "7b6c7430-1d17-49b8-80be-31b087a3b75c",
"displayName": "azure-cli-2018-11-09-12-15-59",
"name": "http://azure-cli-2018-11-09-12-15-59",
"password": "7957f6ca-d33f-4fa3-993a-8fb018c10fe2",
"tenant": "e1be9ce1-c3be-436c-af1d-46feecf854cd"}
We also create an azure storage container to store the Terraform state file. This is required to have multiple devops working on the same infrastructure through a shared storage configuration.
az storage container create -n tfstate --account-name=‘csb07ea84f60ca4x4f66xad4’ --account-key=‘Wo27SNUV3Bkanod424uHStXjlch97lQUMssKpIENytbYsUjU3jscz9SrVogO1gClUZd3qvZs/UwBPqX0gJOU8Q==‘
We now define a set of variables that will be used by terraform to provision our resources.
We also describe the variables that will be output by the execution of our terraform script.
# output.tf
output "client_key"{
value = "${azurerm_kubernetes_cluster.k8s.kube_config.0.client_key}"}
output "client_certificate"{
value = "${azurerm_kubernetes_cluster.k8s.kube_config.0.client_certificate}"}
output "cluster_ca_certificate"{
value = "${azurerm_kubernetes_cluster.k8s.kube_config.0.cluster_ca_certificate}"}
output "cluster_username"{
value = "${azurerm_kubernetes_cluster.k8s.kube_config.0.username}"}
output "cluster_password"{
value = "${azurerm_kubernetes_cluster.k8s.kube_config.0.password}"}
output "kube_config"{
value = "${azurerm_kubernetes_cluster.k8s.kube_config_raw}"}
output "host"{
value = "${azurerm_kubernetes_cluster.k8s.kube_config.0.host}"}
We first initialize the terraform state.We then check the plan before it get executed.We now ask terraform to create all the resources described in the .tf files including the AKS Kubernetes cluster.
$ terraform init
$ terraform plan
$ terraform apply
We know have our running managed Azure Kubernetes cluster(AKS). We define a shell script file containing the set of variables required to run kubectl (the kubernetes client)
more setvars.sh
#!/bin/shecho"Setting environment variables for Terraform"exportARM_SUBSCRIPTION_ID="07ea84f6-0ca4-4f66-ad4c-f145fdb9fc37"exportARM_CLIENT_ID="7b6c7430-1d17-49b8-80be-31b087a3c75c"exportARM_CLIENT_SECRET="7957f6ca-d33f-4fa3-993a-8fb018c11fe1"exportARM_TENANT_ID="e1be9ce1-c3be-436c-af1d-46feecf854cd"exportTF_VAR_client_id="7b6c7430-1d17-49b8-80be-31b087a3b76c"exportTF_VAR_client_secret="7957f6ca-d33f-4fa3-993a-8fb019c10fe1"exportKUBECONFIG=./azurek8s
$ . ./setvars.sh
$ echo"$(terraform output kube_config)"> ./azurek8s
This will basically export the kubernetes configuration file required to be able to use the kubectl command. We can now start to use the kubectl kubernetes client. Let us create a kubernetes secret containing the mariadb password.
$ az aks get-credentials --resource-group azure-k8stest --name k8stest
$ az aks browse --resource-group azure-k8stest --name k8stest
We now create a persistent volume claim. This is very important for MariaDB as MariaDB is a stateful application and we need to define the storage used for persisting the database. We then deploy the mariadb docker container which will use this physical volume for the database storage. we then create a service to expose the database.
Once the service is created the service discovery can be used. Kubernetes offers an internal dns and a ClusterIP associated with the the service. This model make a lot of sense as it abstract us from the pod IP address. Once you have created a kubernetes MariaDB service it can be accessed from another container running inside this same cluster. In that case a mysql client.
$ kubectl expose deployment mariadb --type=NodePort --name=mariadb-service
$ kubectl run -it--rm--image=mariadb --restart=Never mysql-client -- mysql -h mariadbservice -ppassword1
It is also possible to expose the mariadb service through a public IP. This is of course something usually not done for security reasons. kubernetes asks Azure to create a load balancer and a public IP address that can then be used to access the mariaDB server.
$ kubectl expose service mariadbservice --type=LoadBalancer --name=mariadb-service1 --port=3306--target-port=3306
$ mysql -h 104.43.217.67 -u root -ppassword1
In the scenario we presented the infrastructure is described through code (terraform hcl language). We then use the kubernetes client and yaml kubernetes configuration file to declaratively describe software objects configuration.
It makes a lot of sense to use a managed version of kubernetes as Kubernetes itself is a standard building block that offers the same features on all cloud providers. Kubernetes being standardize with this approach we keep the freedom to run the same open source software stack (here MariaDB) across different cloud providers .
How to rapidly provision a MariaDB in the cloud ? Various option are available.
A very effective approach is to provision MariaDB with Terraform. Terraform is a powerful tool to deploy infrastructure as code. Terraform is developed by Hashicorp that started their business with the very successful Vagrant deployment tool. Terraform allows you to describe through HCL langage all the components of you infrastructure. It is aimed to make it easier to work with multiple cloud providers by abstracting the resources description. Keep on reading!
Oracle has done a great technical work with MySQL. Specifically a nice job has been done around security. There is one useful feature that exists in Oracle MySQL and that currently does not exist in MariaDB.
Oracle MySQL offers the possibility from within the server to generate asymetric key pairs. It is then possible use them from within the MySQL server to encrypt, decrypt or sign data without exiting the MySQL server. This is a great feature. This is defined as a set of UDF (User Defined Function : CREATE FUNCTION asymmetric_decrypt, asymmetric_encrypt, asymmetric_pub_key … SONAME 'openssl_udf.so';). Keep on reading!