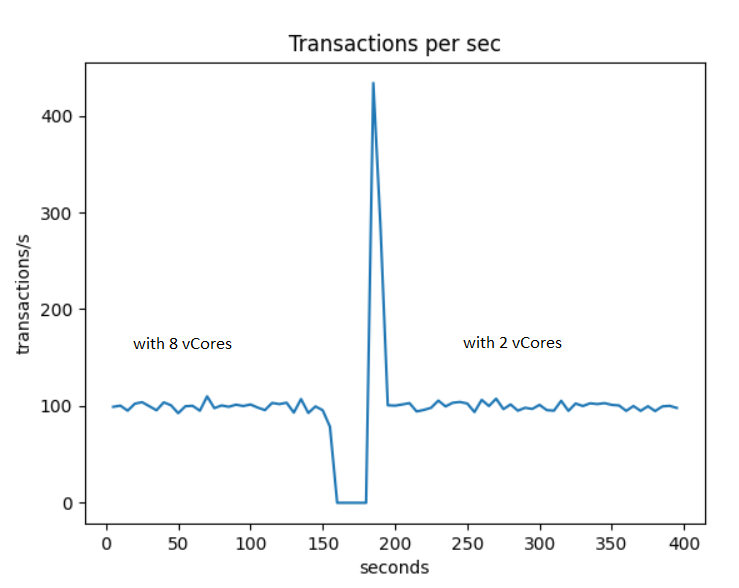
Azure Database for MySQL is a PaaS offer. It has a specific architecture that relies on a gateway. This has a huge advantage in the way it handle High availability. If a server fails it will automatically restart. The storage for the database is highly resilient and will be reconnected to the new server. You get HA out of the box without having to care about replica and failover handling.
if we look at a connection to a Azure Database for MySQL it is different from a usual MySQL connection.
mysql -h mysqlpaasmaster.mysql.database.azure.com \
-u sbtest@mysqlpaasmaster -p \
--ssl-mode=REQUIRED
we notice :
hostname : mysqlpaasmaster.mysql.database.azure.com
username : sbtest@mysqlpaasmaster
Why do we have the instance name in the username ?
If we look at what the host name is, using the unix host command (dig would also do the trick).
$ host mysqlpaasmaster.mysql.database.azure.com
mysqlpaasmaster.mysql.database.azure.com is an alias for cr5.northeurope1-a.control.database.windows.net.
cr5.northeurope1-a.control.database.windows.net has address 52.138.224.6
The host name is just an alias to a gateway server (it is not an A record in the DNS). So the host you connect to is specific to the database's region but carry no information about the mysql instance you connect to. This explains why when you connect you need to embed the database name into the user name. This is the only way for the gateway to know which instance you want to connect to.
Does this fit with proxySQL ? We might think No. But in fact it works perfectly with ProxySQL. ProxySQL which knows the backends hostnames is able to inject this hostname in the MySQL protocol when talking to the azure gateway. This is possible thanks to the fact that ProxySQL uses MariaDB Connector C to communicate with the gateway. With MariaDB Connector C it is possible in the connection options to add '_server_host' which contains the hostname information. In this way the gateway knows what instance is referenced without having it in the username.
ProxySQL is a fantastic technology widely used on MySQL / MariaDB architectures on premise or in the cloud. It has a nice design with the concept of host groups and query rules used to route queries to the desired backend server (based on port or regex).
To achieve this routing proxySQL uses a set of users that will potentially connect to multiple backends depending on the status of these backends and the routing query rules. This is also the same for the monitoring user that is common to all the backends.
So now to test this how this works with Azure Database for MySQL I have setup a Master with 2 replicas (that can be geo replica in another region if you wish). I have created a single user 'sbtest' in proxySQL. On this setup I run a simple sysbench to inject traffic. I use the oltp_read_write.lua script to generate insert, update, delete and select to validate that the read write splitting is working correctly. And it works like a charm 🙂
Here are the host groups, 10 for writes and 20 for reads. Hostgroup 20 contains the 2 replicas plus the master that can also be used for reads(if you want it to focus on write you can put a low weight). Hostgroup 10 contains only the master :
MySQL > SELECT hostgroup_id,hostname,STATUS,comment,use_ssl FROM mysql_servers;
+--------------+--------------------------------------------+--------+-------------+---+
| hostgroup_id | hostname | STATUS | comment |use_ssl
+--------------+-----------------,---------------------------+--------+-------------+----
| 10 | mysqlpaasmaster.mysql.database.azure.com | ONLINE | WRITE GROUP | 1 |
| 20 | mysqlpaasreplica1.mysql.database.azure.com | ONLINE | READ GROUP | 1 |
| 20 | mysqlpaasreplica2.mysql.database.azure.com | ONLINE | READ GROUP | 1 |
| 20 | mysqlpaasmaster.mysql.database.azure.com | ONLINE | WRITE GROUP | 1 |
+--------------+--------------------------------------------+--------+-------------+---+
4 ROWS IN SET (0.00 sec)
Here is the single user used for all the backends.
MySQL > SELECT username,password,active,use_ssl,default_hostgroup FROM mysql_users;
+----------+----------+--------+---------+-------------------+
| username | password | active | use_ssl | default_hostgroup |
+----------+----------+--------+---------+-------------------+
| sbtest | password | 1 | 0 | 10 |
+----------+----------+--------+---------+-------------------+
1 ROW IN SET (0.00 sec)
And here are the query rules to route the queries to the right backend.
MySQL > SELECT rule_id,match_digest,destination_hostgroup FROM mysql_query_rules;
+---------+-----------------------+-----------------------+
| rule_id | match_digest | destination_hostgroup |
+---------+-----------------------+-----------------------+
| 1 | ^SELECT .* FOR UPDATE | 10 |
| 2 | ^SELECT .* | 20 |
+---------+-----------------------+-----------------------+
2 ROWS IN SET (0.00 sec)
Metrics data has also been collected inside the stats schema. We see that master and replicas have received their share of sysbench queries.
MySQL > SELECT hostgroup, srv_host,Queries FROM stats_mysql_connection_pool;
+-----------+--------------------------------------------+---------+
| hostgroup | srv_host | Queries |
+-----------+--------------------------------------------+---------+
| 10 | mysqlpaasmaster.mysql.database.azure.com | 472 |
| 20 | mysqlpaasreplica1.mysql.database.azure.com | 415 |
| 20 | mysqlpaasmaster.mysql.database.azure.com | 402 |
| 20 | mysqlpaasreplica2.mysql.database.azure.com | 422 |
+-----------+--------------------------------------------+---------+
4 ROWS IN SET (0.00 sec).
Through the stats we also get the digest of all the queries run and on wich hostgroup they ran. We can see here that all INSERT, UPDATE,DELE were sent to the Write hostgroup and the SELECT to the Read hostgroup.
SELECT hostgroup, username, digest_text FROM stats_mysql_query_digest;
+-----------+----------+-------------------------------------------------------------+
| hostgroup | username | digest_text |
+-----------+----------+-------------------------------------------------------------+
| 10 | sbtest | INSERT INTO sbtest5 (id, k, c, pad) VALUES (?, ?, ?, ?) |
| 10 | sbtest | DELETE FROM sbtest2 WHERE id=? |
| 10 | sbtest | UPDATE sbtest2 SET c=? WHERE id=? |
| 20 | sbtest | SELECT c FROM sbtest5 WHERE id BETWEEN ? AND ? ORDER BY c |
| 20 | sbtest | SELECT SUM(k) FROM sbtest4 WHERE id BETWEEN ? AND ? |
...
In the monitor schema we will find data that has been collected by the 'monitoruser'. In the monitor schema we can find log data for connect, ping, read_only ... Here for example the ping data to check the availability of the backends :
MySQL > SELECT hostname FROM mysql_server_ping_log;
+--------------------------------------------+------+------------------+------------+
| hostname | port | time_start_us | ping_success_time_us |
+--------------------------------------------+------+------------------+------------+
| mysqlpaasreplica1.mysql.database.azure.com | 3306 | 1591785759257052 | 20088 |
| mysqlpaasreplica2.mysql.database.azure.com | 3306 | 1591785759269801 | 19948 |
| mysqlpaasmaster.mysql.database.azure.com | 3306 | 1591785759282430 | 19831 |
I hope this helped you understand how ProxySQL work with Azure Database for MySQL/MariaDB.
The use of proxySQL on Azure with Azure Database for MySQL/MariaDB definitely brings a lot of value.